


Dodatno produbljujemo naš serijal o umjetnoj inteligenciji i pitamo se kako će uređaji bazirani na njoj suvislo pričati, svirati, pjevati?!?!?!?! Donosimo i jako puno korisnih linkova i YouTube radova.
U prošlom nastavku naše male serije o umjetnoj inteligenciji (AI) bavili smo se računalnim vidom i prepoznavanjem objekata. Mogli bi zaključiti da današnja razina tehnologije prilično dobro ispunjava postavljene zadatke i da AI „dobro vidi“.
No što je s audio osjetilima i njima povezanim temama – sluhom, govorom, pa onda i pjevanjem i glazbom. Pokazati će se da je to prilično tvrd orah, prepun zamki i iako je i tu ostvaren veliki napredak, kreiranje fluidnog računalnog govora (pogotovo ne samo na engleskom) još će počekati.
Dakle u ovom nastavku bavimo se problemima jezika i stvaranja glazbe, dok ćemo se u sljedećem upustiti u dublje probleme razumijevanja teksta i kognitivnih funkcija umjetne inteligencije.
Zašto je jezik tako kompliciran za AI
„Jezik je vjerojatno jedan on najtežih problema u modernoj znanosti – nitko točno ne zna kako funkcionira, kako je nastao – no ipak svi ga možemo koristiti“ – Michael Corballis
Prema ustaljenoj definiciji jezik je komunikacijski sustav sastavljen od znakova i gramatičkih pravila koji se koristi za međusobnu komunikaciju i razmjenu značenja. No problem s jezicima je da pravila nisu jednoznačna, u svim jezicima ne postoje iste kategorije: nemaju svi jezici iste glasove, neki jezici imaju padeže, a neki ne; svi jezici nemaju iste vrste riječi (npr. ponegdje nema pridjeva kao posebne vrste, mnogi jezici nemaju članove, itd.).
Pa onda imamo problem da je svaki govornik jedinstven (dakle ima nas 7,5 milijardi i svi smo različite fizičke građe, a onda i glasovnih mogućnosti). A kao da ni to nije dovoljno, i naš glas je različit u ovisnosti o dobi dana, da li smo zdravi ili bolesni, a posebno ako smo jučer glasnije proslavljali pobjedu našeg omiljenog nogometnog tima. I konačno, svaki tekst može biti različito izgovoren, brzo ili sporo, s raznim naglascima, osjećajno ili nezainteresirano itd.
I na kraju, jezik je snažno i kulturološki određen, bogatstvo jezika i pojmova proizlazi i od okruženja u kojem živimo te društvenim vrijednostima. Tako npr. Eskimi imaju preko 20 različitih naziva za snijeg i led (odnosno preko 400 sa svim varijacijama), a mi samo dva. Po drugoj strani nemaju riječi za rat ili ljubomoru, a brojni primitivni narodi nemaju koncept trgovine pa onda ni pojam novca kao njene osnove.
Kad bolje promislimo, čudo je da se uopće međusobno razumijemo, a kamo li da još naučimo AI govoriti 🙂 . No, ipak ima nade …
Evolucija jezika

Kako je već rečeno, nije posve jasno kako smo i zašto naučili govoriti, no genetska razlika između čovjeka i čimpanze je samo 1.2 %, a razlika se najviše oslikava u veličini mozga i stupnju razvoja vokalnog aparata i fonatornih funkcija glasa (ostalo je manje-više isto). E sad, da li se prije 2 milijuna godina najprije razvio mozak pa je on utjecao na razvoj sposobnosti govora, ili je bilo obratno pa je mogućnost govora doprinijela bržem razvoju mozga – nije razriješeno, mada ova druga varijanta ima više pristalica.
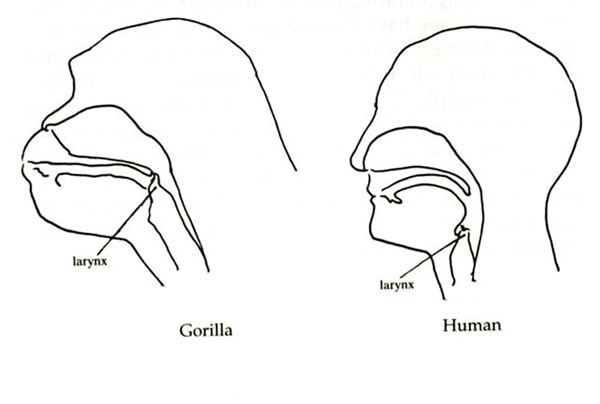
Kako su rani ljudi živjeli u malim zajednicama, relativno rano je nastala potreba za komunikacijom – jednostavno je na neki način trebalo objasniti gdje se nalazi hrana ili gdje se šeće medvjed ili lav koji nam radi o glavi.
Relativna nerazvijenost vokalnog aparata u tim ranim danima ljudske rase nije bila neki poseban problem, s desetak različitih zvukova i glasova već se može iskombinirati neka osnovna značenja i opisati tipična životna situacija.
Dan Everett nas vodi kroz tu ranu povijest čovječanstva u sjajnom predavanju.
No, prođe nekoliko milijuna godina, i zbog gomile razloga, taj jedan proto jezik se razgranao u tisuće varijanti i desetine tisuća dijalekata.
Danas u svijetu postoji oko 7 100 jezika (Izvor: UNESCO), no jedna trećina je ugrožena jer ih govori manje od 1 000 govornika. Po drugoj strani više od pola svjetskog stanovništva govori samo 23 jezika.
Možda ta ekspanzija jezika djeluje kao nešto što je donijelo samo komplikacije, pa će nam pojednostavljenje (ne bi li bilo super da svi govorimo isti jezik?!) biti od koristi – no upravo je suprotno, jezik nas čini onom što jesmo, gubitak svakog jezika ili narječja predstavlja veliku štetu, kao što su monokulture pogubne za prirodu, tako bi bila i dominacija samo jednog jezika pogubna za razvoj ljudske civilizacije.
OK, imamo dakle hrpu jezika, svi su posve različiti, a imamo i one milijarde govornika i što sad ?
NLP – Natural Language Processing (iliti obrada prirodnog jezika)
Obrada prirodnog jezika složeno je polje i sjecište je umjetne inteligencije, računalne lingvistike i informatike, a na sljedećem dijagramu se može uočiti koje su komponente.
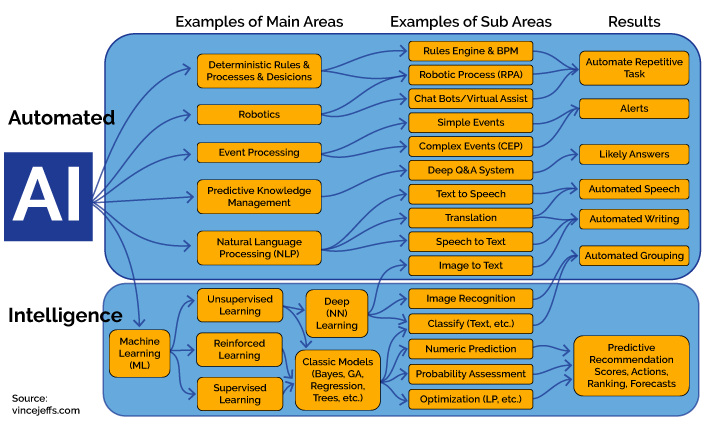
Definicija NLP je:
- Obrada prirodnog jezika (NLP) je “sposobnost strojeva za razumijevanje i tumačenje ljudskog jezika način na koji je napisan ili govoren”.
- Cilj NLP-a je da računalo/strojevi budu „inteligentni“ kao ljudska bića u razumijevanju jezika.
NLP je vrlo složeno područje, no generalno se problem svodi na tri različite razine jezičke analize:
- Sintaksa – Koji je dio danog teksta gramatički ispravan?
- Semantika – Koje je značenje danog teksta?
- Pragmatika – Koja je svrha teksta?
NLP se osim toga bavi i različitim aspektima jezika kao što su:
- Fonologija – to je sustavna organizacija zvukova u jeziku.
- Morfologija – Studija je formiranja riječi i njihovog odnosa jednih s drugima.
I na kraju dolazimo do razumijevanja izgovorene riječi i teksta kroz različite pristupe:
- Distributivni – Koristi opsežne statističke taktike strojnog učenja i dubokog učenja na uzorcima teksta.
- Okvirni – Rečenice koje su sintaktički različite, ali semantički iste, predstavljene su unutar strukture podataka (okvira) za neku promatranu situaciju.
- Teoretski – Ovaj pristup temelji se na ideji da se rečenice odnose na stvarni svijet (npr. nebo je plavo), a dijelovi rečenice mogu se kombinirati kako bi dobili kompletno značenje.
- Interaktivno učenje – uključuje pragmatični pristup i korisnik je odgovoran za učenje računala da korak po korak nauči jezik u interaktivnom okruženju za učenje.
Pretvorba govora u tekst
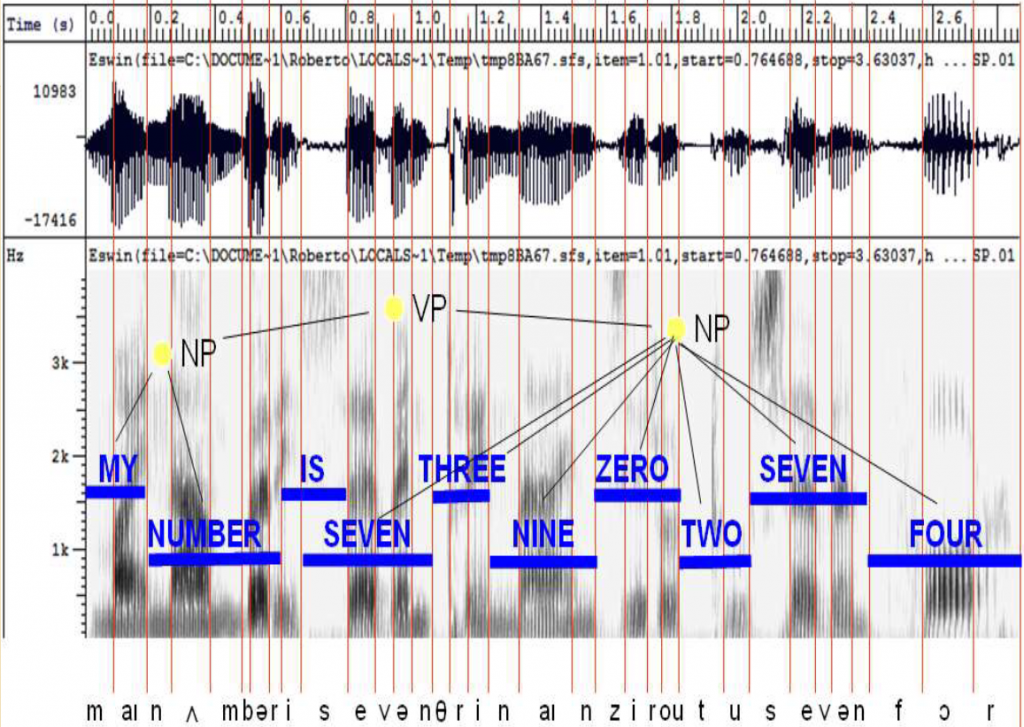
Prvi korak u NLP obrada je pretvaranje govora u digitalnu formu (tekst) s kojom kasnije možemo manipulirati. Detalji prelaze okvire ovog članka, no prema modelu prikazanom na sljedećoj slici, proces se svodi na snimanje govora i njegovu interpretaciju uz pomoć akustičkog i lingvističkog modela:
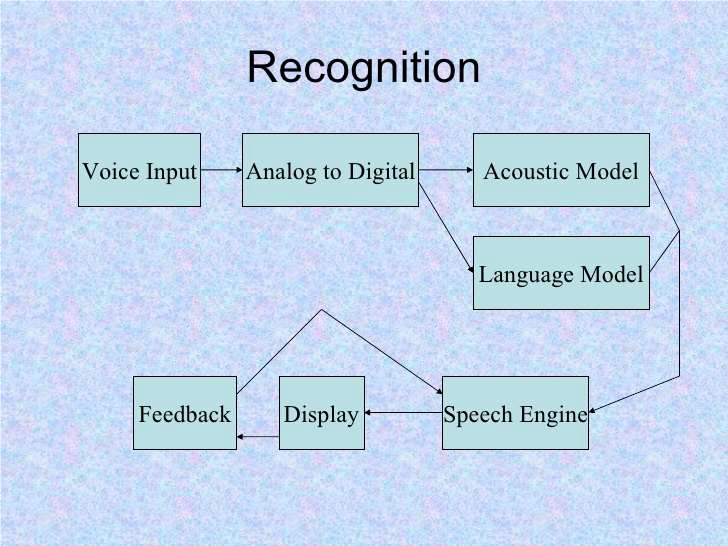
Akustički model nastaje snimanjem audio zapisa govora i njihovih transkripcija teksta te korištenjem softvera za stvaranje statističkih prikaza zvukova koji čine svaku riječ. Koriste se HMM (Hidden Markov Model) statistički modeli koji ispisuju niz simbola ili količina. HMM se koriste u prepoznavanju govora jer se govorni signal može promatrati kao kratkotrajan stacionarni signal što olakšava njegovu interpretaciju.
Jezični model je datoteka koja sadrži vjerojatnosti sljedova riječi. Jezični se modeli koriste kod aplikacija za diktiranje ili upravljanje a u cilju poboljšanja prepoznatog teksta.
Pretjerali smo s teorijom 🙂 – kako to funkcionira u praksi ?
Pa prva AI „materijalizacija“ čitave ove priče je kroz nastanak i brzo širenje ChatBot-ova raznih vrsta. Ideja je bila napraviti sustav koji bi mogao zamijeniti ljude primarno u kontekstu davanja repetitivnih i standardiziranih informacija, u centrima podrške, online servisima, inteligentnim uputama i slično.
Chatboti su posljednjih godina postali izuzetno popularni velikim dijelom zahvaljujući dramatičnom napretku u strojnom učenju i drugim temeljnim tehnologijama kao što je obrada prirodnog jezika. Današnji su Chatboti pametniji, responzivniji i korisniji – a vjerojatno ćemo ih vidjeti još više u narednim godinama.
Princip rada Chatbota je relativno jednostavan – najprije treba razumjeti što korisnik hoće, pronaći odgovor i vratiti ga korisniku, i to sve skupa u formi dijaloga u realnom vremenu. Komponente su prikazane na sljedećoj slici, a u nastavku je objašnjenje čemu služe.
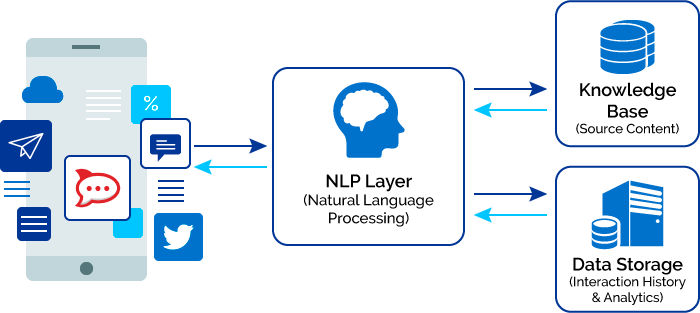
Baza znanja – Sadrži bazu podataka koje se koriste za opremanje Chatbota informacijama potrebnim za kreiranje odgovore na upite korisnika. Obično sadrže informacije iz uske (servisne) domene
Baza podataka – sadrži povijest interakcije Chatbota s pojedinim korisnicima i kompletnu analitiku kojom se može prilagoditi određenoj kategoriji korisnika
NLP sloj – prevodi korisničke upite (iz slobodne forme – govor ili tekst) u informacije koje se mogu koristiti za odgovarajuće odgovore.
Aplikacijski sloj – to je aplikacijsko sučelje koje se koristi za interakciju s korisnikom (vizualno, tekstualno ili govorno), mobilno ili web bazirano.
Chatbotovi uče svaki put kada uspostave interakciju s korisnikom pokušavajući uskladiti korisničke upite s podacima u bazi znanja koristeći strojno učenje.
Kako sagraditi vlastitog Chatbota?
Ma i nije tako komplicirano, samo slijedite upute kroz ovaj sjajan vodič za IBM Watson i Android platformu. Na linku ovdje.
U AI Labu Zavičajnog muzeja Drenove možete uživo vidjeti i isprobati razne Chatbotove kreirane uz pomoć IBM, Pythona, RASA, Tensorflowa i drugih zanimljivih tehnologija.
Kome se ne da iz naslonjača, može probati i nekoliko zanimljivih online chatbotova s kojima možete sjajno ćakulati (većinom su dostupni kao mobilne aplikacije):
ALICE – prvi ChatBot – i danas je dostupan (obavezno isprobati)
Insomno bot – ako ne možete spavati
Disney Zootopia – duhovit
UNICEF U-report: ozbiljna priča, kako unaprijediti društvo
MEDWHAT: odgovara na pitanja iz područja zdravlja ili medicine
WYSA: psihijatar bez kauča
WOEBOT: još jedan psihijatar
Vidjeli smo da je jezik/govor prilično kompliciran, a što je s glazbom? Ta pjevušiti je lakše nego pričati!!
AI i Glazba
Tradicionalno se glazba i jezik tretiraju kao različiti psihološki fenomeni. Ova dvojnost ogleda se u starijim teorijama gdje se vjerovalo da su govorne funkcije lokalizirane u lijevoj, a glazbene funkcije u desnoj hemisferi mozga.
Ovo je gledište posljednjih godina promijenjeno uglavnom zbog pojave modernih tehnika slikovnog snimanja mozga i poboljšanja neurofizioloških mjera za ispitivanje moždanih funkcija. Osim toga se pojavljuju novi dokazi da govorne funkcije mogu imati koristi od glazbenih funkcija i obrnuto, tako da slika nije baš jednoznačna.
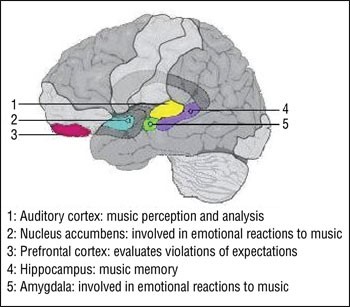
Prema tome možemo smatrati da je proces učenja glazbe sličan procesu učenja jezika. Pokaže se u kontekstu umjetne inteligencije da je čak i jednostavniji jer su muzička pravila nešto određenija od jezičnih.
Svijet je krcat knjiga koje se vrte oko pojmova sklada, melodije, ritma i analize o različitim žanrovima i onome što ih čini da su nam ugodni. Klasična glazba posebno je prepuna različitih sustava i skupova pravila koje skladatelji odluče upotrijebiti ili razvrgnuti.
No naravno glazba je ujedno i inovacija. Postojala su percipirana pravila kada su Beatlesi prvi put pokrenuli i odlučili ignorirati tzv. pravila i znamo kako je to promijenilo lice glazbe. Još prije njih Mozart je bio manje tradicionalan u svom načinu pisanja glazbe. Mnogi su rekli da je koristio previše nota. No za našu priču o umjetnoj inteligenciji važno je pitanje što je kreacija.
AI sustav koji je „odslušao“ stotine sati Mozarta (ili Beatlesa, svejedno) može bez problema „uhvatiti“ stil autora i primjenjujući pravila komponiranja uz uvođenje slučajnosti – stvarati nova djela.
Nije li invencija i nova glazbena ideja samo neki slučajni preskok u mozgu kompozitora? Koja je razlika ?
Preslušajte sami pa procijenite:
AI Beatles:
AI Pianist:
Kako AI uči kreirati baroknu muziku
Deep Bach
Tensorflow Magenta
Koliko je tehnologija napredovala pokazuje velika dostupnost komercijalnih servisa za generiranje glazbe:
OpenAi – MuseNet
I za kraj, meni najbolje Magenta Tensorflow – za kišnog vikenda možete sve isprobati: https://magenta.tensorflow.org/demos.
Kutak za štrebere:
Sve tajne NLP i kompleksne problematike jezika možete otkriti u izvrsnoj i besplatnoj knjizi autora Daniela Jurafskya i Jamesa H. Martina!







