


Nastavljamo naš nabrijani AI serijal. Uživajte u igri i eksperimentiranju s najvećim područjem današnjice.
U prošlom nastavku (vidjeti ovdje!) naše male serije o umjetnoj inteligenciji (AI) bavili smo problemom sluha, govora, a na kraju smo malo i muzicirali. Sada je vrijeme da se malo više pozabavimo pisanom riječju, odnosno dotaknemo vrlo složeno područje razumijevanja teksta. Pa ako razumijemo tekst, možda je to neki začetak pameti?
Pismo – zašto pišemo
Za početak se trebamo pitati – zašto uopće pišemo, što će nam to. Kažu neki jutjuberi da više nema potrebe za pisanjem, samo se fino zavalimo i slušamo njih, ne trebaju nam knjige i pisanje? To drži vodu dok ne nestane struje, onda smo opet na prašnjavim knjigama. 🙂
Priča o pismu počinje jako davno, najvjerojatnije u doba sumerske civilizacije i kako to obično biva kod nas ljudi – nastala je zbog imovine. Gdje ima ljudi, postoji i proizvodnja nekih dobara pa onda postoji i razmjena. A ako postoji razmjena onda moramo voditi računa i o količinama, a kad ta količina postane velika – ne može se sve zapamtiti. I onda se netko sjetio da bi se količine neke robe mogle zapisivati na glinene pločice kojih su mogli imati u izobilju.
A dodatna prednost je i trajna pohrana – kad se zapeče, pločica postaje skoro vječna (za razliku od naših CD-ova ili USB stikova), pa nema kasnijeg muljanja – skoro kao Blockchain ;).
Prvi zapisi su bili crteži, no tijekom vremena su se (zbog bržeg pisanja i boljeg korištenja prostora na pločicama) pretvorili u simbole i u konačnici u slova.
Jedno od važnih svojstava jezika je kombiniranje pojmova (riječi), odnosno činjenica da s relativno malim brojem osnovnih elemenata možemo raditi nova značenja.
S time su počeli Sumerani, pa primjerice kombinacije riječi hrana i voda zapravo predstavlja ribu i sl. Suvremeni majstori tog postupka su Nijemci koji imaju zanimljive riječi poput Betäubungsmittelverschreibungsverordnung, što bi otprilike značilo pravilnik koji propisuje preskripciju anestetika.
No imati samo hrpe riječi može stvoriti priličan nered i nejasnoće u komunikaciji, i zato su odmah uspostavljena pravopisna pravila. Ona nam omogućavaju bolje razumijevanje zapisa, daju nam kontekst vremena kad se nešto dogodilo, tko su akteri, kakvi su njihovi osjećaji i što je uopće sadržaj teksta koji čitamo. Da razumijevanje teksta uopće nije trivijalno ljudima, a kamoli računalima, svjedoči činjenica da postoje čitave metode i tečajevi za to:
No kako je ovo priča o AI-u, dosta povijesti, idemo u 21. stoljeće.
Kao i uvijek malo (?!) teorije za početak
Obrada (NLP) i razumijevanje prirodnog jezika NLU postala je važan dio modernih AI sustava. Te teme smo se dotaknuli i prošli put u kontekstu chatbotova, no sada je tema obrada teksta ili cijelih dokumenata. Strojevi mogu dobro obraditi strukturirane podatke. Ali kada je u pitanju rad sa tekstom slobodnog oblika, zadaća postaje iznimno složena.
Cilj NLP-a je razviti algoritme koji računalima omogućuju razumijevanje teksta slobodne forme i osigurati rudimentarno prepoznavanje sadržaja.
Jedna od najizazovnijih stvari koja se odnosi na obradu prirodnog jezika slobodnog oblika je veliki broj varijacija. Kontekst igra vrlo važnu ulogu u razumijevanju pojedine riječi ili rečenice. Ljudi su sjajni u tim stvarima jer smo trenirali dugi niz godina. Sve svoje dosadašnje znanje odmah koristimo da bismo razumjeli kontekst i znali o čemu druga osoba govori.
Kako bi riješili taj problem, istraživači NLP-a započeli su s razvijanjem različitih platformi od kojih je najpopularnija NLTK (Natural Language Toolkit), i vrlo je jednostavna za korištenje. Da bismo stvorili aplikacije koje uz pomoć strojnog učenja mogu „razumjeti“ tekst, moramo prikupiti veliku hrpu primjera, a zatim osposobiti algoritam za obavljanje različitih zadataka poput kategorizacije teksta, analiziranja osjećaja ili modeliranja dijaloga. Ovi su algoritmi osposobljeni za otkrivanje obrazaca u ulaznim tekstualnim podacima i njihovim transformacijama.
Kako pripremiti tekst za analizu uz pomoć NLTK
Kad imamo posla s tekstom, moramo ga na početku raščlaniti na manje dijelove radi lakše analize. Ovdje dolazi u našu priču tokenizacija. To je postupak dijeljenja ulaznog teksta na skup dijelova poput riječi ili rečenica. Dobiveni dijelovi zovu se tokeni ili žetoni. Ovisno o tome što želimo napraviti sa tekstom, možemo definirati vlastite metode dijeljenja teksta u više tokena.
Evo primjera, tokenzirajmo sljedeću rečenicu: “Želiš li znati kako tokenizacija funkcionira? Napišimo koju rečenicu pa probajmo!”

Kako vidimo, naše tekst razbijen je na dvije rečenice ili na skup riječi. Naravno ovo je trivijalan primjer, ali dobro opisuje princip. Sljedeći korak je svođenje riječi na njihov osnovni oblik kako bi mogli lakše identificirati značenje.
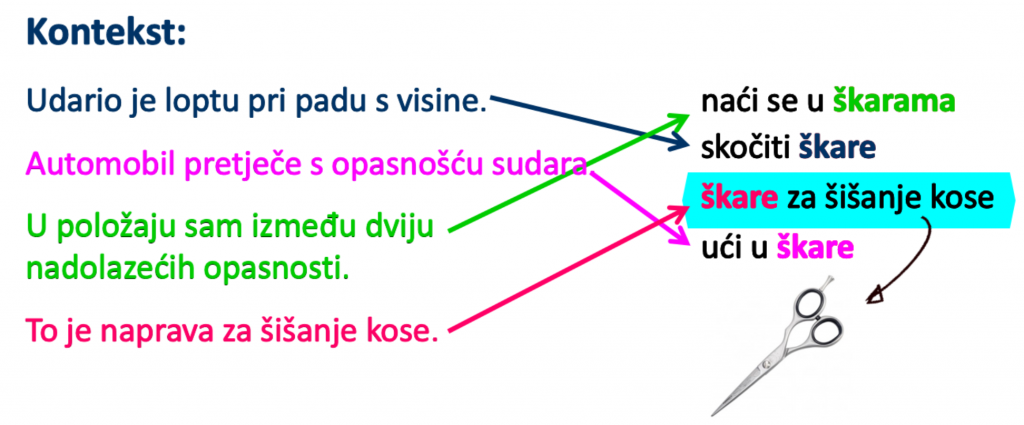
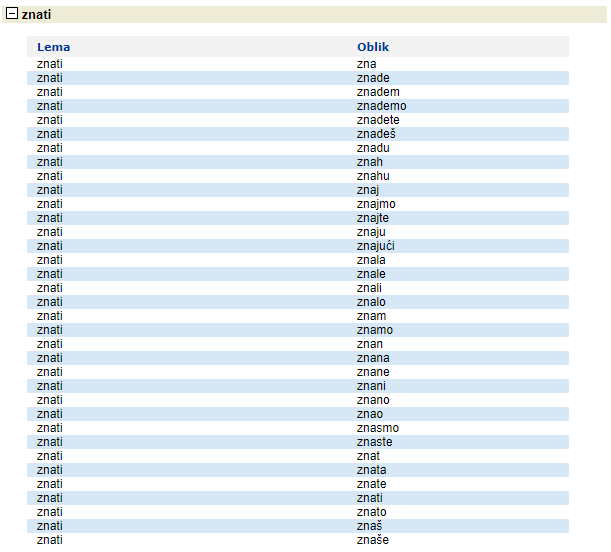
Taj postupak se zove lematizácija (proces konvertiranja riječi iz svoje osnovne tekstualne forme u normaliziranu lingvističku formu – lemu, pri čemu se dodatno konzultira i rječnik za pojedini jezik. Hrvatski jezik je prilično kompliciran, pogledajte varijacije samo jedne riječi iz našeg primjera – znati.
Druga metoda dobivanja osnovne riječi zove se korjenovanje riječi (engl. stemming). Korijen riječi dobiven ovim procesom ne mora biti jednak morfološkom korijenu riječi, jer se proces bazira na prepoznavanju tipičnih sufiksa i prefiksa i njihovoj eliminaciji. Lematizácija je napredniji postupak i danas se najčešće koristi.
Ok, pronašli smo osnovne riječi i što sad?
Vrijeme je za postupak koji se zove Označavanje dijelom govora (POS) (ili gramatičko označavanje) a koristi se za određivanje klasa svake riječi, tj. za prepoznavanje riječi kao imenice (NN), glagola (VBD), pridjeva (JJ), priloga (RB) ili odredbenice (DT), što će nam pomoći kod određivanja pravog smisla rečenice.
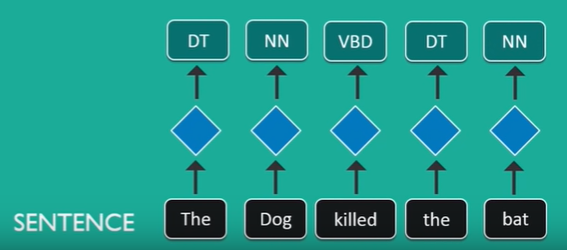
Za engleski jezik to radi skoro savršeno, evo jedan EPK primjer:
Forming part of the pre-programme of the ‘Borders – Between Order and Chaos’, this exhibition commemorates the 100th anniversary of d’Annunzio’s occupation of Rijeka by personifying the city as a woman and alluding to his many mistresses, who were left physically and emotionally drained after he ended their relationship, just like the city of Rijeka.
Nakon obrade dobijmo prilično pouzdanu interpretaciju klase svake riječi:

A što znače pojedine kratice – saznajte detaljnije ovdje.
Zvuči zamršeno – ne brinite, blizu smo cilju!
Osim pravopisno-gramatičkog raščišćavanja značenja riječi u rečenici, dobro bi nam došao još jedan sloj klasifikacije značenja. To se zove Prepoznavanje imenovanog entiteta (eng. NER – name entity recognition), odnosno uvođenje dodatnih kategorija (poput lokacije, organizacije, osoba, vrijednosti i slično) koje bolje određuju značenje pojedinih riječi kad obrađujemo velike količine teksta.
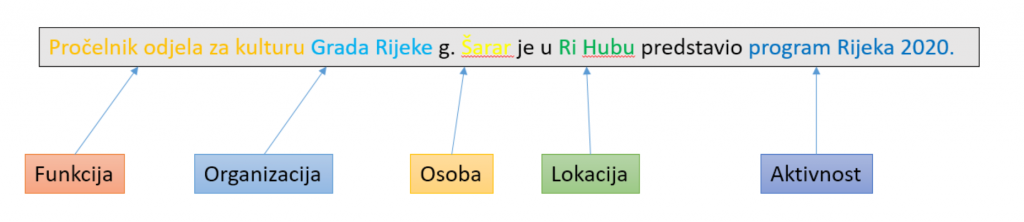
I eto nas na posljednjem koraku – nakon što smo veliki tekst razbili na dijelove, maksimalno klasificirali i razumjeli pojedine riječi, vrijeme je da pokušamo obraditi neki tekst.
I konačno – umjetna inteligencija !
Umjetna inteligencija u kontekstu obrade teksta donosi nam pregršt algoritama sa famoznim NLTK alatom. Na primjer, recimo da želimo predvidjeti pripada li određena rečenica sportu, politici ili znanosti. Da bismo to učinili, gradimo najprije korpus podataka i „učimo“ algoritam. Ovaj se algoritam potom može koristiti za zaključivanje o nepoznatim podacima. U našem primjeru skinuti su testni podaci nekoliko tisuća novinskih vijesti koje su iskorištenje za treniranje sustava, a sad ćemo pokušati odrediti o čemu se radi u tekstu:
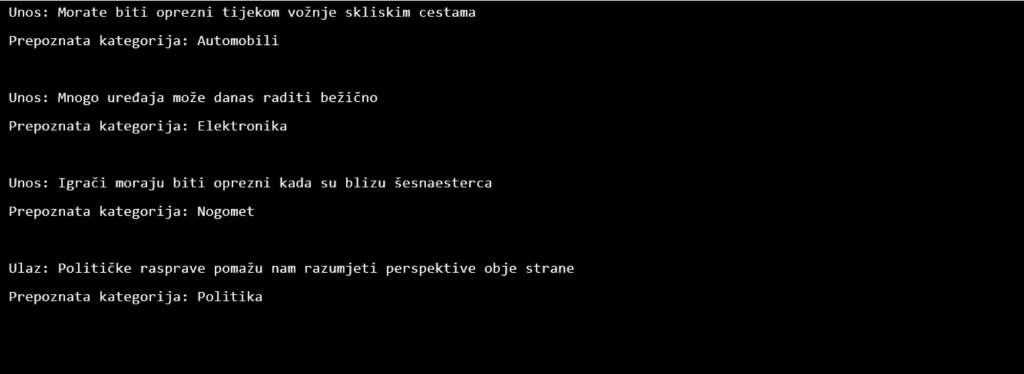
Dakle vidimo iz ovog primjera da AI prilično dobro „shvaća“ o čemu se radi u testnoj rečenici. Da li nam može odrediti recimo spol iz imena (Alexander, Danielle, David, Cherly):

Nije loše, a da vidimo što je s detekcijom osjećaja ?!
Detekcija osjećaja je postupak utvrđivanja osjećaja određenog dijela teksta. Primjerice, pomoću njega se može utvrditi je li dojam o nekom filmu pozitivan ili negativan. Ovo je jedna od najpopularnijih aplikacija obrade prirodnog jezika. Često se koristi i za analizu marketinških kampanja, ispitivanja javnog mnijenja, (ne)popularnosti političara na društvenim mrežama itd.
Pogledajmo onda kako odrediti osjećaj u filmskim kritikama.
Kao i u prethodnom slučaju za početak skinemo bazu sa filmskim kritikama. Koristit ćemo Naive Bayes klasifikator. Najprije moramo izvući sve riječi iz teksta, obraditi ih prema prethodnim naputcima, i na kraju osposobiti Naive Bayes da klasificira pozitivne i negativne kritike. Osposobiti znači kreirati liste „pozitivnih“ i „negativnih“ riječi koje će mu služiti kao orijentacija. Nakon završenog procesa učenja možemo napisati neku svoju kritiku i vidjeti kako će ju AI procijeniti:
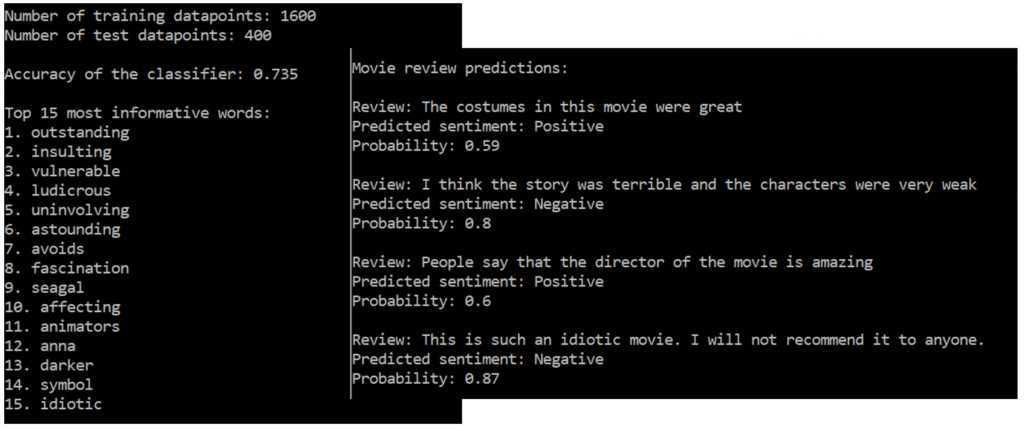
Pa, prilično je dobro pogodio naše osjećaje i mišljenje o nekom filmu. Broj 0,59 ili 0,8 predstavlja sigurnost AI da je pogodio neki osjećaj ( 1 znači da je posve siguran).
I za kraj postavlja se logično pitanje – ako AI „razumije“ riječi, slaganje rečenica, može pronaći neka jezična pravila – da li može i sam početi stvarati neki tekst. Odgovor je pozitivan, i ne samo to, nego je to i najzabavniji dio ove cijele priče!
AI kao pisac
Za početak isprobajte Transformera super pametni generator teksta baziran na analizi milijuna WEB stranica. I istovremeno ishodište skandala jer je omogućio kreiranje sustava za proizvodnju lažnih vijesti s obzirom da je njegov kod otvoren.
Problem s Transformerom je njegova prilična uvjerljivost koja proizlazi iz velike količine podataka koji su Googleu dostupni no i naprednih RNN i LSTM algoritama. Kako je cijela priča posložena pogledajte na njihovom oficijelnom videu.
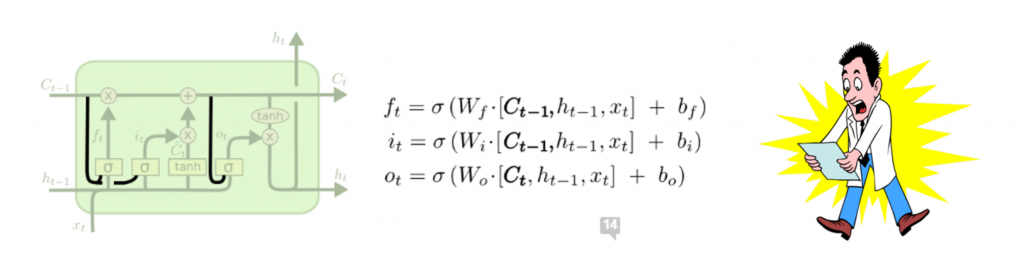
Iako na prvi pogled djeluje komplicirano, osnovna ideja RNN i LSTM je da (kao i ljudi) pamte neka prethodna stanja ili informacije koje nam mogu koristiti kod daljnjih predviđanja. Izvrstan video to detaljno objašnjava.
Dakle, ti AI tekst generatori jednostavno prepoznaju što ste napisali i onda u nastavku pokušaju kreirati neki tekst koji bi se logično nastavio – i to radi iznenađujuće dobro.
Naravno, nije trebalo dugo čekati da se pojave razne druge verzije poput DeepAI ili sustava koji iz podataka prikupljenih na Projektu Gutemberg kreira izvrsnu poeziju!
Da je ova tema sazrjela i za komercijalizaciju potvrđuje jedan od prvih AI generatora članaka – AI pisac čije su usluge za sitne novce već dostupne.
Uglavnom, novinari – loše vam se piše!
ČAI – čakavska umjetna inteligencija
Zanimljiv projekt provodi se u okviru drenovskog AI laboratorija, gdje se bave s kreiranjem Čakavske umjetne inteligencije. Dio je to Rijeka 2020 programskog pravca 27 susjedstava u kojem sudjeluje ekipa Susjedstva Drenova (maheri za AI) u suradnji sa Susjedstvom Kastav (maheri za čakavski). Ideja je kreirati ČAI-ja, pronicljivog, samouvjerenog i povremeno bezobraznog Chatbota koji govori (osim engleski i hrvatski) i našim čakavskim narječjem.
Samo ga treba pogoditi u pravu žicu . 🙂
On je kreiran po metodologiji koja je ranije objašnjena, a trenutni rezultat možete provjeriti i sami.

ČAI je hibrid između klasičnog Chatbota kreiranog uz pomoć IBM Watson tehnologije i naprednog open source sustava baziranog na neuronskim mrežama – Chatterbota.
Chatterbotova glavna prednost je baziranost na strojnom učenju, te primjena programskog jezika Python što olakšava razvoj. To osigurava drugu važnu funkcionalnost – neovisnost o govornom jeziku, odnosno sposobnost da ga se istovremeno „podučava“ i za rijedak jezik/narječje poput čakavskog.
Početna instanca ChatterBota započinje bez znanja kako komunicirati i koja su jezična pravila. U interaktivnom načinu rada, svaki put kada korisnik unese neku izjavu, u bazu se sprema unesen tekst pitanja kao i odgovor.
Kako ChatterBot prima sve više ulaznih podataka, povećava se broj odgovora na koje se može suvislo odgovoriti i točnost svakog odgovora u odnosu na ulaznu izjavu. Program odabire najvjerojatniji odgovarajući odgovor pretraživanjem najbliže poznate izjave koja odgovara ulazu, a zatim vraća najvjerojatniji odgovor na tu izjavu na temelju statističke obrade svih podataka. Odgovori se mogu dodatno poboljšavati korištenjem eksternih izvora informacija poput pretraživanja Googlea ili Wikipedije, odnosno kreiranjem tzv. domenskih narativa (u slučaju Drenove to su neke lokalne priče o granici, poznatim osobama iz povijesti itd.).
U slučaju ČAI-ja uz interaktivno učenje, koriste se i predefinirati setovi dijaloških podataka na čakavskom jeziku, koji omogućavaju lakše kreiranje konverzacija. Oni su podijeljeni u razne kategorije, a ovo je primjer iz psihologije:
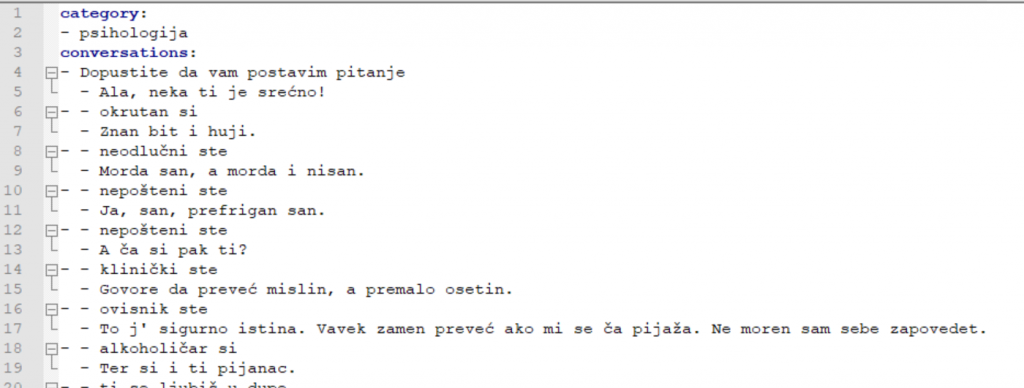
Zaključno, konačni rezultat i nije tako loš s obzirom na trenutno vrlo male količine dijaloških podataka, no tijekom naredne godine intenzivno će se raditi na obogaćivanju ČAI-jevog čakavskog korpusa kako bi bio posve spreman za izazove tijekom EPK RIJEKA 2020. 🙂
I tko zna, možda se ovaj zabavni i umjetnički projekt pretvori u nešto „pravo“ – a to je da konačno dobijemo pošten sustav za automatsko prevođenje sa stranih jezika, prepoznavanje govora i diktata, te kreiranje TTS (text-to-speech) na hrvatskom književnom jeziku i narječjima.
To čekamo samo 30 godina…
Kutak za štrebere:
Definitivan izvor za objašnjenje cijele NLP priče je odličan tečaj ekipe iz fast.ai, a video materijali koji prate predavanja su na:







