


Naš ekspert za pitanja umjetne inteligencije (a nije robot!) donosi novi paket znanja. Na prvu ne djeluje lagano, ali nitko nije rekao da će doba kibernetičara biti – banalno.
U uvodnom članku naše male serije o umjetnoj inteligenciji (AI) vidjeli smo da je ona danas prilično sposobna odrađivati mnoge poslove jednako dobro, ako ne i bolje od ljudi.
U biti sve se svodi na primanje nekih ulaznih informacija, njihovu obradu i potom prezentaciju rezultata ili izvođenje neke aktivnosti. S obzirom da je kreirana po istim principima funkcioniranja ljudi, treba i ista ili slična osjetila. U primjerima koje ćemo obrađivati radi se o vidu i sluhu. To će nam omogućiti da prepoznajemo oblike, čitamo i interpretiramo tekst, transformiramo i crtamo slike i na kraju pomalo i govorimo.
A sve to uz pomoć malih i jeftinih minijaturnih računala RaspberryPi ili kraće RPi, dostupnih svakome i vrlo prisutnih u našim školama.
Svi navedeni primjeri dostupni su u AI Labu u Zavičajnom muzeju Drenove.
Prepoznavanje slika i računalni vid
Za početak malo teorije kako to rade ljudi, a kako strojevi.
Biološki vid
Ovo je primarno priča o računalnom vidu, no valja se podsjetiti nekih osnova biološkog vida.
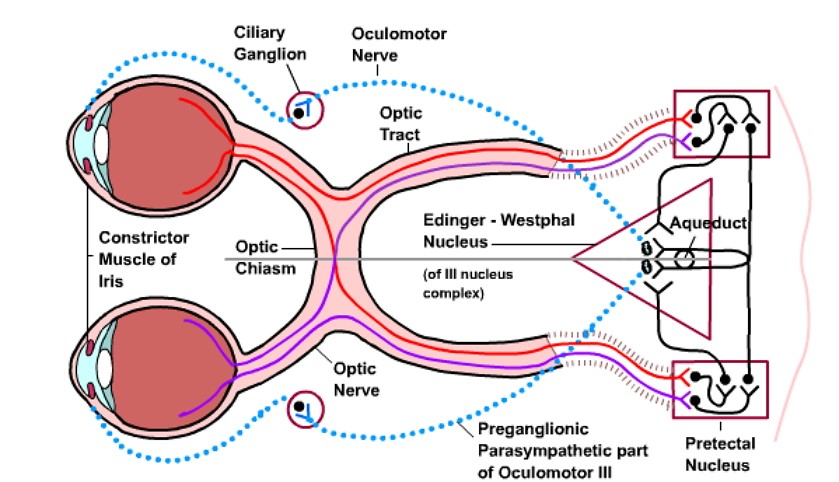
Svjetlo najprije prolazi kroz šarenicu. Šarenica je dio oka što se prilagođava količini svjetlosti koja ulazi u oko – regulator za automatsko osvjetljenje. Svjetlo tada prelazi na leću, koja se rasteže i komprimira mišićima kako bi fokusirala sliku. To je slično automatskom fokusu na digitalnom fotoaparatu. S dva oka dobivamo stereo vid, koji je vrlo važan za našu prostornu orijentaciju.
Svjetlo tada ulazi u kontakt s posebnim neuronima u oku (čunjiće za boju i štapiće za svjetlinu) koji pretvaraju svjetlosnu energiju u kemijsku energiju. Ovaj proces je kompliciran, ali krajnji rezultat je „paljenje“ neurona u skladu s uzorcima koji se šalju u mozak putem optičkog živca. Čunjići i štapići su biološke verzije piksela. No, za razliku od kamere u kojoj je svaki piksel jednak, to ne vrijedi za ljudsko oko. Zanimljivo je kako su informacije iz ljudskog oka zapravo izmiješane. Slika je obrnuta od leće, čunjići i štapovi nisu jednako raspoređeni, a niti jedno oko ne vidi istu sliku!
Taj cirkus mora razriješiti sam mozak. Fizički reorganizirajući pristigle informacije, može ponovno sastaviti sliku u nešto nama razumljivije. Prikupila se osnovna vizualna informacija, koja se zatim ponovno obrađuje na još višoj razini. Mozak se sada pita, što ja stvarno vidim? Znanost još nije u potpunosti riješila taj problem, no pretpostavlja se da mozak drži veliku bazu podataka s referentnim informacijama – što predstavljaju pojedini objekti. Mozak ‘promatra’ nešto, zatim prolazi kroz referentnu knjižnicu kako bi donio zaključke o onome što se promatra. Referentna knjižnica se puni cijeli život, a najviše u najranijoj dobi kada se dijete uči govoriti – to je trenutak kada se stvaraju asocijacije između slika i značenja.
Strojni (računalni) vid
Načelno je princip računalnog vida ekvivalentan ljudskom. Prvi korak je snimanje slike. CCD senzor snima podatke kao tok informacija, čitajući pojedine svjetlosne receptore koji su složeni 2D matricu i u isto vrijeme pohranjuje sve prikupljene informacije jednu datoteku. Sve slike imaju X komponentu i Y komponentu. U svakoj točki pohranjena je vrijednost boje.
Ako je slika crno-bijela (binarna), pohranit će se ili 1 ili 0 na svakoj lokaciji. Ako je boja u sivim tonovima, pohranit će raspon vrijednosti. Ako je slika u boji (RBG), pohranit će skupove vrijednosti. Kako bi se smanjila veličina zapisa primjenjuju se različite metode komprimiranja podataka, no kako to nije važno za ovu našu priču – ovaj put preskačemo složenu problematiku kompresije :).
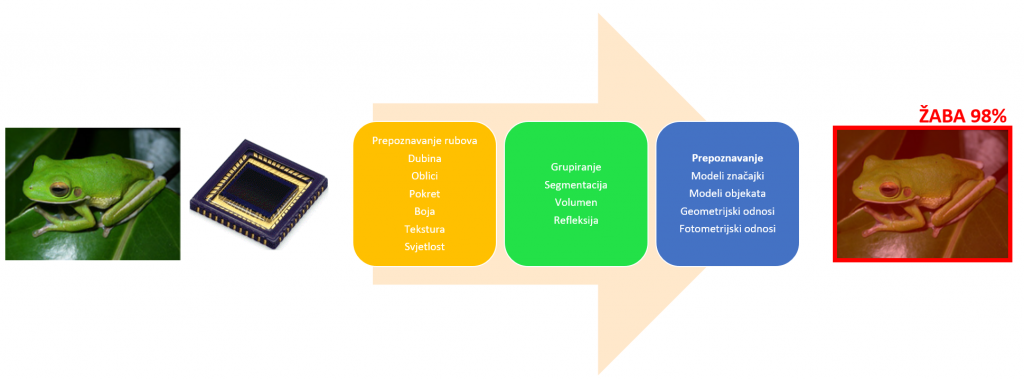
Nakon što smo dobili skupove vrijednosti koje predstavljaju našu sliku potrebno je pokušati utvrditi što se na slici nalazi. To je tipično više stupanjski postupak, a mi ćemo pogledati samo nekoliko najvažnijih dijelova. Prvi postupak je tipično prepoznavanje rubova, a to je tehnika za lociranje rubova objekata u sceni. To može biti korisno za lociranje horizonta, kuta objekta, sljedećeg bijelog retka ili za određivanje oblika objekta koji ćemo podrobnije analizirati.

Nakon nekoliko koraka (segmentacije, grupiranje itd.) dolazimo konačno na otkrivanje oblika i prepoznavanje uzoraka. Detekcija oblika zahtijeva pretraživanje u bazi podataka matematičkog prikaza oblika koje želite otkriti. Osnovni oblici su vrlo jednostavni, ali kada uđete u složenije oblike (prepoznavanje uzoraka) morat ćete koristiti i analizu vjerojatnosti.
Na primjer, pretpostavimo da je vaš algoritam potreban za prepoznavanje između 10 različitih plodova (samo po obliku) kao što su jabuka, naranča, kruška, trešnja itd. Kako biste to učinili? Svi su kružni, ali nisu savršeno kružni. I nisu sve jabuke izgledale isto.

Koristeći vjerojatnost, možete izvesti analizu čiji će rezultat biti da promatrano voće odgovara u 90% karakteristikama jabuke, a samo u 60% karakteristike naranče, tako da je vjerojatnije da se radi o jabuci. To je računalna verzija ‘obrazovanog nagađanja’. Ova metoda je poznata kao detekcija svojstava.
Posebna je priča prepoznavanje ljudskih oblika – posebno lica, koje se temelji na sposobnosti prepoznavanja, a zatim i mjerenja različitih značajki lica.
Svako lice ima brojne, prepoznatljive znamenitosti, različite vrhove i doline koje čine crte lica. Sustav definira te orijentire kao čvorne točke. Svako ljudsko lice ima približno 80 čvorova. Neki od tih mjera koje softver mjeri su:
· Udaljenost između očiju
· Širina nosa
· Dubina ušica
· Oblik jagodica
· Duljina linije čeljusti
Ove čvorne točke mjere se stvaranjem numeričkog koda, nazvanog faceprint, koji predstavlja lice u bazi podataka. U priloženom videu vidi se da je moguće utvrditi i smjer gdje je usmjeren pogled što se može iskoristiti za razne aplikacije
Što je Tensorflow i zašto je cool?
Tensorflow je Googleova platforma otvorenog koda koja je namijenjena strojnom učenju, a sastoji se od seta alata, setova otvorenih podataka i programerske zajednice koja omogućava jednostavni razvoj i implementaciju naprednih AI sustava. To je ujedno i ključna prednost u odnosu na druge konkurentske tehnologije.
Naziv Tensorflow potječe iz svojstva da sustav uzima ulaz kao višedimenzionalni niz, također poznat kao tenzor. Stoga možete izgraditi neku vrstu dijagrama tijeka operacija (nazvanog Graph) koje želite izvršiti na tom ulazu. Ulazni podaci ulaze na jednom kraju, a zatim teku kroz ovaj sustav višestrukih operacija i transformacija i na koncu izlazi na drugi kraj kao obrađeni rezultat.
Kako možemo natjerati računala da korektno odrađuju vizualne analize kada ne znamo ni kako to sami radimo? Tu nam sad pomaže strojno učenje, u našem slučaju uz korištenje Tensorflow tehnologije. Umjesto pokušaja da iznesemo detaljne upute za korak po korak kako interpretirati slike i prevesti ih u računalni program, dopuštamo računalu da to sam shvati. Cilj strojnog učenja je omogućiti računalima da nešto učine bez izričitog objašnjenja kako to učiniti. Mi samo pružamo neku vrstu opće strukture i dajemo računalu mogućnost da uči iz iskustva, slično onome kako mi ljudi učimo iz iskustva.
U biti radi se o problemu optimizacije. Počinjemo s definiranjem modela i dobivanjem početnih vrijednosti za njegove parametre. Zatim hranimo skup podataka sa svojim poznatim i ispravnim oznakama za model. To je faza obuke. Tijekom ove faze model opetovano razmatra podatke o treningu i stalno mijenja vrijednosti svojih parametara.
Cilj je pronaći vrijednosti parametara koje rezultiraju najboljim mogućim rezultatom. Ova vrsta obuke, u kojoj se ispravno (poznato) rješenje koristi zajedno s ulaznim podacima, naziva se nadzirano učenje. Postoji i učenje bez nadzora, u kojem je cilj naučiti iz ulaznih podataka za koje nisu dostupne poznate oznake, ali to je izvan opsega ovog članka.
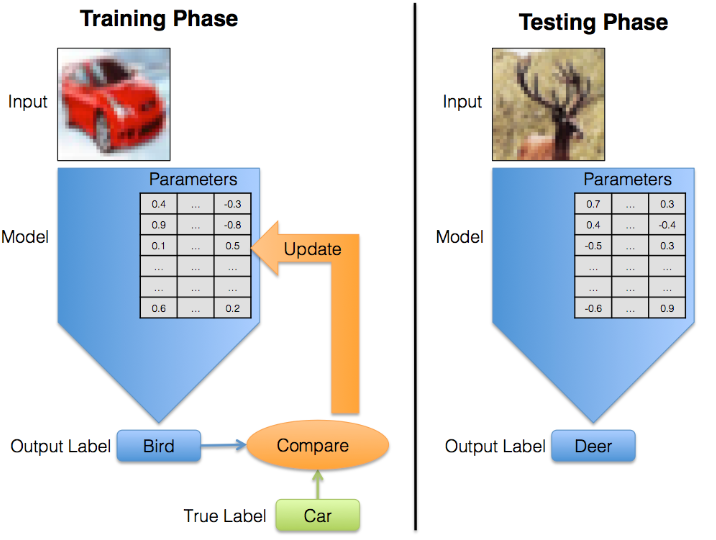
Nakon završetka obuke, vrijednosti parametara modela više se ne mijenjaju, a model se može koristiti za klasificiranje slika koje nisu bile dio skupa podataka za obuku. U praksi stvar je relativno jednostavna, našem AI-ju pokažemo dovoljan broj slika određenog objekta i on će biti u stanju prepoznati o čemu se radi kada mu u vidno polje ubacimo, mačku, autić ili avion. Što mu više slika pokažemo – bit će precizniji u pogađanju!

Taj postupak treniranja sustava možemo obaviti sami (ako imamo jako, jako puno vremena i dovoljno jako računalo s popularnom Nvidia grafičkom karticom ili možemo iskoristiti već neke napravljene modele. Detaljan postupak učenja možete pogledati u odličnom YouTube videu i doista nije pretjerano teško konfigurirati sustav.
No, za potrebe eksperimentiranja postoje brojni gotovi modeli koje se može skinuti s repozitorija (najbolji za RPi su tipa Mobilnet).
Mobilnet modeli nam daju dobar kompromis između brzine i točnosti prepoznavanja ako se izvodi na malim računalima tipa RPi 2 ili 3. Ako vam je na raspolaganju ozbiljnija oprema poput RPi 4 ili Jetson Nano možete isprobati i ostale modele…
Nije neka nauka, probajte i sami 🙂
Konfiguriranje RPi-ja za eksperimentiranje s prepoznavanjem oblika detaljno je pojašnjeno u sljedećem videu – iako na prvi pogled djeluje komplicirano samo treba slijediti detaljne upute i za sat vremena ćemo imati posve funkcionalan sustav.
U većini slučajeva odziv sustava bit će oko 1 sekunde, što je zapravo dovoljno za većinu eksperimentalnih primjena.

Glavna prednost korištenja RPi-ja je što on ima moćno ulazno/izlazno sučelje pa je vrlo jednostavno ovaj primjer nadograditi s nekom konkretnom akcijom. Primjerice, ako na slici prepoznamo lopova (!) upalimo alarm, ili prepoznamo mačku i otvorimo zaklopac na vratima.
Ugodna zabava !
Kutak za štrebere:
Definitivan izvor za objašnjenje algoritama koji se kriju iza obrade računalnog prepoznavanja slika je izvrsna i besplatna knjiga Richarda Szeliskog, velike face u tom području!







